Google has recently been launching its artificial intelligences at the rate of a factory siren. Gemini 3 was just released in November. It is now followed by Gemini 3.1 Pro, which is currently in preview to developers and the general population, and is touted as a significant improvement in the reasoning and judgment. Every new release is reported to think better than the previous one.
Deep Think Enhancements
In the recent past Google talked about improvements in a feature that it refers to as Deep Think. We are told that it was this 3.1 Pro that powered those refinements. The new model scores 44.4 percent in Humanity Last Exam, a test of specialized and challenging knowledge. The previous one was 37.5 percent. The GPT 5.2 of OpenAI is 34.5 percent. The numbers are precise to the decimal point and this gives them an aura of certainty but the average reader might not be able to imagine what such percentages really mean.
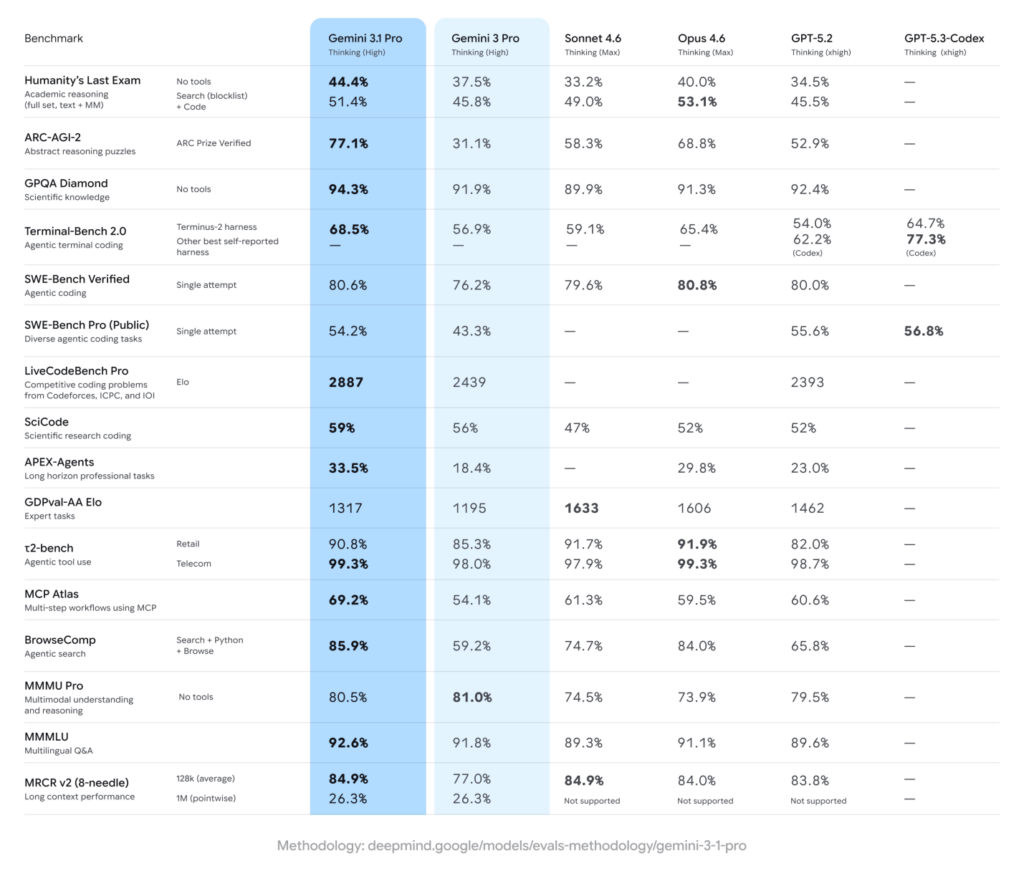
There is also the case of ARC-AGI-2, a set of strange logic puzzles, structured in such a way that no machine can be able to use memorized patterns to solve them. In this test, Gemini 3 had fared badly with 31.1 percent whereas competitors were well above. The new model has a new score of 77.1 percent, which is over two times higher than its previous score. On paper, at least, the change is dramatic. It gives Google the evidence it requires to make the claim that it is progressing once again.
Arena Rankings and Rival Models
In earlier announcements, Google was quick to declare that its latest creation had already climbed toward the top of the Arena leaderboard, once known as LM Arena. This time the boast is absent. In the category of text, Claude Opus 4.6 stands four points higher, at 1504, than Gemini 3.1 Pro.
In coding tasks the margin is wider still: Opus 4.6, Opus 4.5, and GPT 5.2 High each place themselves ahead of Google’s new model. The standings, however, rest upon preference rather than proof. The Arena is governed by user votes, and users are inclined to favour what appears convincing, whether or not it is entirely sound.
To illustrate the supposed advance, Google has drawn attention to the model’s talent for producing graphics and simulations. The sample SVG images displayed in its demonstration are undeniably tidy and well-composed, though they are, of course, selected specimens. Large benchmark scores and carefully arranged exhibitions make an orderly case for progress.
Yet the question remains a practical one: will the ordinary user perceive a change? For those who put broad and abstract inquiries to the system, and who expect answers that are measured and exact, Gemini 3.1 Pro is likely to respond with greater depth than its immediate predecessor. Whether that improvement will be felt in daily use is another matter.
Enterprise Rollout, Developer Access, and Pricing Details
Those who employ Gemini in the creation of agent-like workflows may notice the change most plainly. In the APEX-Agents benchmark, the new 3.1 Pro model has nearly doubled its previous mark, a result that Google presents as evidence of practical advance rather than theoretical promise. The revision is being introduced, in preview, through AI Studio and the Antigravity IDE. Corporate customers will encounter it within Vertex AI and under the banner of Gemini Enterprise. Ordinary users, for their part, can access 3.1 Pro through the Gemini application and NotebookLM as of today.
The terms remain unaltered. Developers will pay the same rate as before, $2 for input and $12 for output per million tokens. The limits, too, are unchanged: a context window of one million input tokens and sixty-four thousand output tokens. In this respect, progress has not brought greater expense, nor has it widened the frame within which the model operates. If Google follows its customary course, a corresponding 3.1 revision of the swifter and less costly Flash model will likely appear before long. Such has been the rhythm of its releases, and there is little reason to expect a departure from it now.
Final Words
Google has handed itself the baton in the fast-paced race of artificial intelligence. Gemini 3.1 Pro comes with a better score on benchmarks, better reasoning assertions and a new stack of decimal-point precision to demonstrate its value. On paper, the jump between rather average puzzle-solver and logic virtuoso is dramatic enough to be applauded. As a matter of fact, though, the applause need not be thunderous. Benchmarks are glowing, leaderboards are shaking, and well-groomed demos shine like showroom models in the bright light.
But to the average user, it might not seem so revolutionary and more like an enhancement. Gemini 3.1 Pro does not reinvent the artificial intelligence rules. It pushes them along, confidently and competitively. In this quick-paced competition, the smallest of gains can be heard as victory speeches.